GLUS: Global-Local Reasoning Unified into A Single Large Language Model for Video Segmentation
* Equal Contribution
TL;DR
We propose GLUS, unify the distinct challenges of Referring Video Object Segmentation, "ref" and "vos", into a simple framework for MLLMs.
Abstract
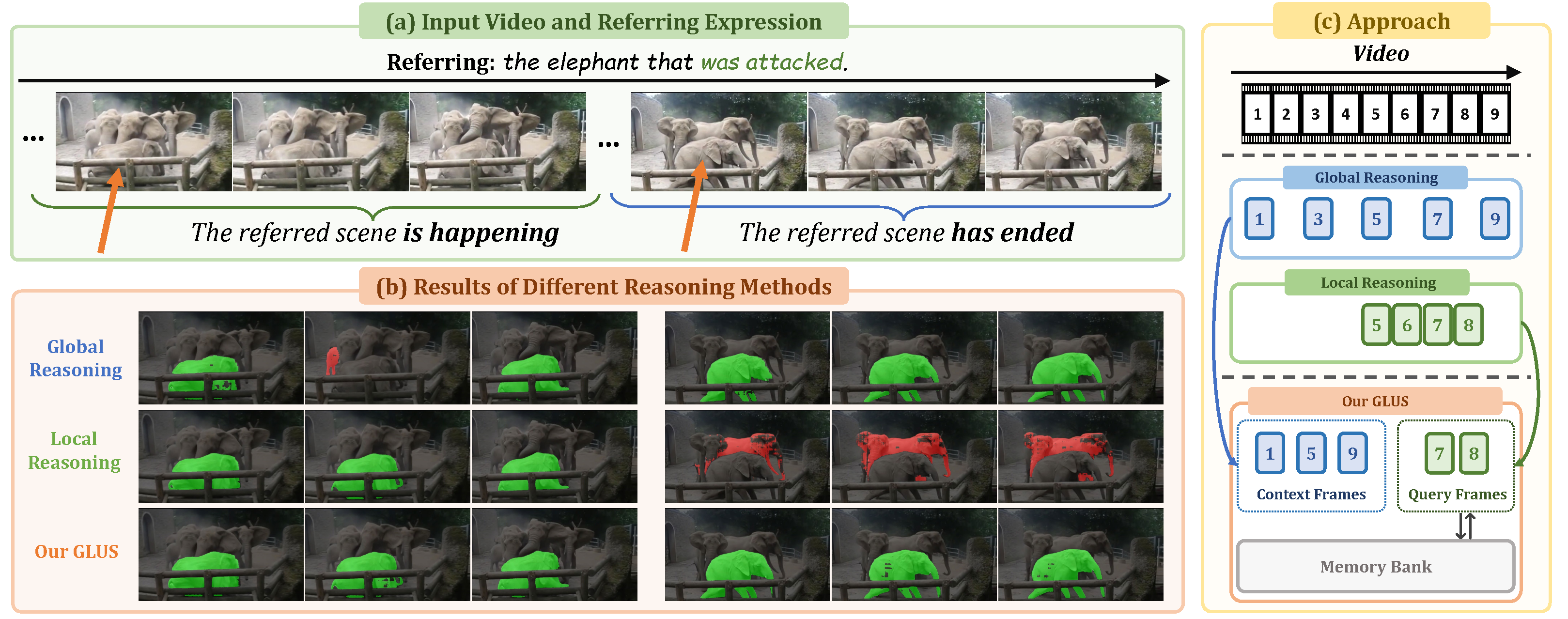
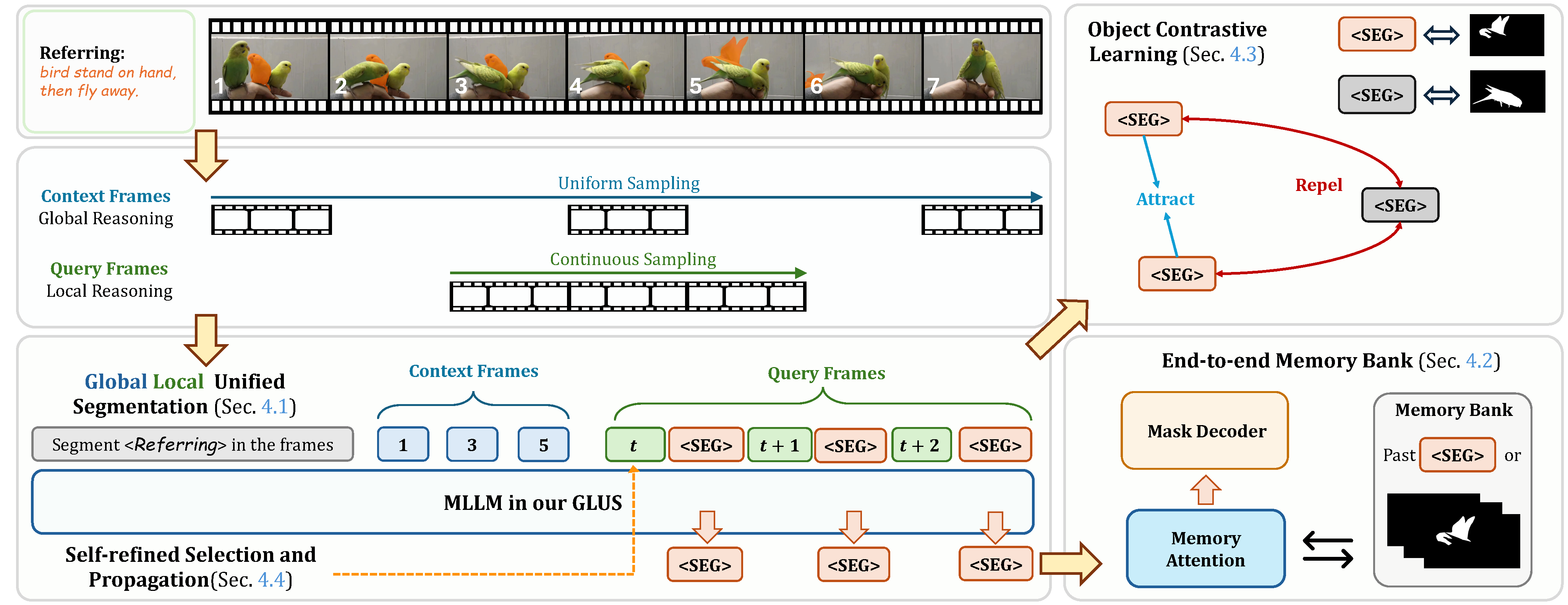
This paper proposes a novel framework utilizing multi-modal large language models (MLLMs) for referring video object segmentation (RefVOS). Previous MLLM-based methods commonly struggle with the dilemma between 'Ref' and 'VOS': they either specialize in understanding a few key frames (global reasoning) or tracking objects on continuous frames (local reasoning), and rely on external VOS or frame selectors to mitigate the other end of the challenge. However, our framework GLUS shows that Global and Local consistency can be Unified into a single video Segmentation MLLM: a set of sparse 'context frames' provides global information, while a stream of continuous 'query frames' conducts local object tracking. This is further supported by jointly training the MLLM with a pre-trained VOS memory bank to simultaneously digest short-range and long-range temporal information. To improve the information efficiency within the limited context window of MLLMs, we introduce object contrastive learning to distinguish hard false-positive objects and a self-refined framework to identify crucial frames and perform propagation. By collectively integrating these insights, our GLUS delivers a simple yet effective baseline, achieving new state-of-the-art for MLLMs on the MeViS and Ref-Youtube-VOS benchmark.
GLUS: Global-Local Unified Reasoning Framework for MLLMs
We demonstrate that unifying global and local reasoning into a single MLLM for RefVOS through the design of context and query frames constitutes a simple yet effective baseline method for MLLM-based RefVOS models. We further introduce plug-and-play object contrastive loss and self-refinement with key frame selectors, enabling MLLM to focus on the correct objects and most relevant frames.
Quantiative Results
Our GLUS trained with only RefVOS datasets realizes competitive performance among MLLM-based approaches with datasets from diverse tasks. With expanded training datasets (ED), our GLUS achieves state-of-the-art performance across RefVOS benchmarks, especially in MeViS consisting of complex video scenarios.
| Method | MeViS | Ref-Youtube-VOS | ||||
|---|---|---|---|---|---|---|
| J&F | J | F | J&F | J | F | |
| Methods without LLMs | ||||||
| URVOS | 27.8 | 25.7 | 29.9 | 47.2 | 45.2 | 49.1 |
| LBDT | 29.3 | 27.8 | 30.8 | 49.4 | 48.2 | 50.6 |
| MTTR | 30.0 | 28.8 | 31.2 | 55.3 | 54.0 | 56.6 |
| ReferFormer | 31.0 | 29.8 | 32.2 | 62.9 | 61.3 | 64.6 |
| OnlineRefer | - | - | - | 63.5 | 61.6 | 65.5 |
| SOC | - | - | - | 67.3 | 65.3 | 69.3 |
| TempCD | - | - | - | 65.8 | 63.6 | 68.0 |
| LoSh | - | - | - | 64.2 | 62.5 | 66.0 |
| LMPM | 37.2 | 34.2 | 40.2 | - | - | - |
| DsHmp | 46.4 | 43.0 | 49.8 | 67.1 | 65.0 | 69.1 |
| Methods with LLMs | ||||||
| LISA-7B | 37.2 | 35.1 | 39.4 | 53.9 | 53.4 | 54.3 |
| LISA-13B | 37.9 | 35.8 | 40.0 | 54.4 | 54.0 | 54.8 |
| TrackGPT-7B | 40.1 | 37.6 | 42.6 | 56.4 | 55.3 | 57.4 |
| TrackGPT-13B | 41.2 | 39.2 | 43.1 | 59.5 | 58.1 | 60.8 |
| VideoGLAMM | 45.2 | 48.1 | 48.2 | - | - | - |
| VideoLISA-3.8B | 44.4 | 41.3 | 47.6 | 63.7 | 61.7 | 65.7 |
| VISA-7B | 43.5 | 40.7 | 46.3 | 61.5 | 59.8 | 63.2 |
| VISA-13B | 44.5 | 41.8 | 47.1 | 63.0 | 61.4 | 64.7 |
| ViLLa | - | - | - | 66.5 | 64.6 | 68.6 |
| GLUS (ours) | 50.3 | 47.5 | 53.2 | 66.6 | 65.0 | 68.3 |
| GLUS (ours) (ED) | 51.3 | 48.5 | 54.2 | 67.3 | 65.5 | 69.0 |
Qualitative Results
We provide qualitative comparisons between the previous state-of-the-art (DsHmp) and our GLUS (without extedning datasets) with the videos in MeViS. Notably, these exam- ples illustrate three challenging aspects of RefVOS: (1) Mo- tion Understanding: RefVOS models have to distinguish similar objects with their motions; (2) Global Reasoning: RefVOS models should be capable of using global reason- ing to segment the objects presented only in a short video clip; (3) Vision-Language Reasoning: RefVOS models should perform vision-language unified reasoning in com- plex scenarios. The examples demonstrate that our GLUS effectively tackles RefVOS in challenging language- guided segmentation cases.